MoE-CAP: Benchmarking Cost, Accuracy and Performance of Sparse Mixture-of-Experts Systems
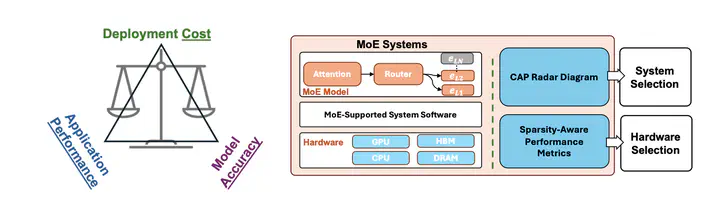 MoE-CAP Framework Overview
MoE-CAP Framework OverviewAbstract
The sparse Mixture-of-Experts (MoE) architecture is increasingly favored for scaling Large Language Models (LLMs) efficiently, but it depends on heterogeneous compute and memory resources. These factors jointly affect system Cost, Accuracy, and Performance (CAP), making trade-offs inevitable. Existing benchmarks often fail to capture these trade-offs accurately, complicating practical deployment decisions. To address this, we introduce MoE-CAP, a benchmark specifically designed for MoE systems. Our analysis reveals that achieving an optimal balance across CAP is difficult with current hardware; MoE systems typically optimize two of the three dimensions at the expense of the third-a dynamic we term the MoE-CAP trade-off. To visualize this, we propose the CAP Radar Diagram. We further introduce sparsity-aware performance metrics-Sparse Memory Bandwidth Utilization (S-MBU) and Sparse Model FLOPS Utilization (S-MFU)—to enable accurate performance benchmarking of MoE systems across diverse hardware platforms and deployment scenarios.
Key Contributions
MoE-CAP introduces a comprehensive benchmarking framework for sparse Mixture-of-Experts systems with three main contributions:
1. MoE System Trade-off Analysis
- Cost-Performance Optimized: Systems that minimize deployment costs while maintaining high throughput
- Accuracy-Cost Optimized: Systems that balance model quality with budget constraints
- Accuracy-Performance Optimized: Systems that maximize both model quality and inference speed
2. Sparsity-Aware Performance Metrics
- Sparse Memory Bandwidth Utilization (S-MBU): Accounts for selective expert activation patterns in memory usage calculations
- Sparse Model FLOPS Utilization (S-MFU): Measures computational efficiency considering sparse expert routing
3. CAP Radar Diagram Visualization
A novel visualization tool that displays the trade-offs between Cost, Accuracy, and Performance across different MoE systems and hardware configurations.
Technical Innovation
The benchmark addresses critical gaps in existing MoE evaluation by:
- Heterogeneous Hardware Support: Evaluating performance across GPUs, CPUs, and mixed-tier memory systems
- Real-world Deployment Scenarios: Including serverless endpoints, elastic infrastructure, and spot-instance pricing
- Comprehensive Model Coverage: Supporting diverse MoE architectures from Switch-C to DeepSeek-R1
Impact and Applications
MoE-CAP enables practitioners to:
- Make informed decisions about MoE system selection and deployment
- Optimize resource allocation for cost-effective LLM serving
- Understand fundamental trade-offs in sparse expert systems
- Predict performance on lower-cost hardware configurations
This work provides essential tools for the growing ecosystem of sparse MoE systems, helping bridge the gap between theoretical model capabilities and practical deployment realities.