(OSDI 2024) ServerlessLLM: Locality-Enhanced Serverless Inference for Large Language Models
Abstract
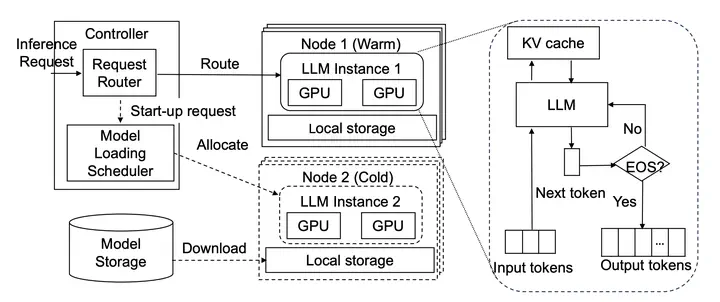
This paper presents ServerlessLLM, a locality-enhanced serverless inference system for Large Language Models (LLMs). ServerlessLLM exploits the substantial capacity and bandwidth of storage and memory devices available on GPU servers, thereby reducing costly remote checkpoint downloads and achieving efficient checkpoint loading. ServerlessLLM achieves this through three main contributions: (i) fast LLM checkpoint loading via a novel loading-optimized checkpoint format design, coupled with an efficient multi-tier checkpoint loading system; (ii) locality-driven LLM inference with live migration, which allows ServerlessLLM to effectively achieve locality-driven server allocation while preserving the low latency of ongoing LLM inference; and (iii) locality-aware server allocation, enabling ServerlessLLM to evaluate the status of each server in a cluster and effectively schedule model startup time to capitalize on local checkpoint placement. Our comprehensive experiments, which include microbenchmarks and real-world traces, show that ServerlessLLM surpasses state-of-the-art systems by 10 - 200X in latency performance when running various LLM inference workloads.