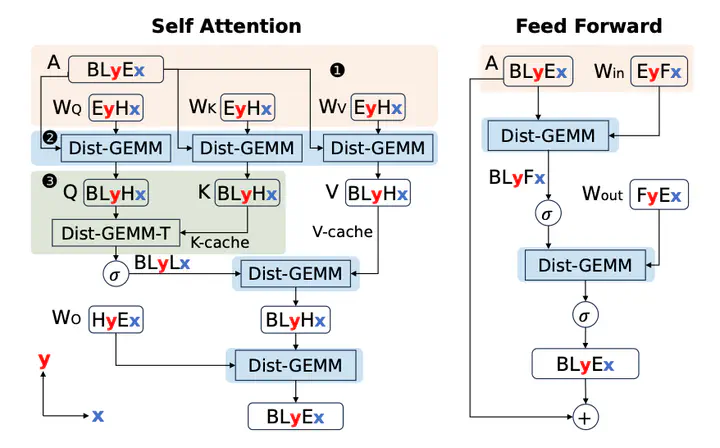
 WaferLLM Architecture Overview
WaferLLM Architecture OverviewAbstract
Emerging AI accelerators increasingly adopt wafer-scale manufacturing technologies, integrating hundreds of thousands of AI cores in a mesh architecture with large distributed on-chip memory (tens of GB in total) and ultra-high on-chip memory bandwidth (tens of PB/s). However, current LLM inference systems, optimized for shared memory architectures like GPUs, fail to exploit these accelerators fully. We introduce WaferLLM, the first wafer-scale LLM inference system. WaferLLM is guided by a novel PLMR model (pronounced as ‘Plummer’) that captures the unique hardware characteristics of wafer-scale architectures. Leveraging this model, WaferLLM pioneers wafer-scale LLM parallelism, optimizing the utilization of hundreds of thousands of on-chip cores. It also introduces MeshGEMM and MeshGEMV, the first GEMM and GEMV implementations designed to scale effectively on wafer-scale accelerators. Evaluations show that WaferLLM achieves up to 200× higher accelerator utilization than state-of-the-art methods. Leveraging a wafer-scale accelerator (Cerebras WSE2), WaferLLM delivers GEMV operations 606× faster and 16× more energy-efficient than on an NVIDIA A100 GPU. For full LLM inference, WaferLLM achieves 10-20× speedups over A100 GPU clusters running SGLang and vLLM.
Key Innovations
WaferLLM represents a breakthrough in large-scale AI inference, introducing the first system designed specifically for wafer-scale architectures:
1. PLMR Model (Plummer)
A novel performance model that captures the unique characteristics of wafer-scale architectures:
- Distributed On-chip Memory: Tens of GB total capacity
- Ultra-high Memory Bandwidth: Tens of PB/s aggregate bandwidth
- Mesh Architecture: Hundreds of thousands of AI cores interconnected
2. Wafer-Scale LLM Parallelism
Revolutionary parallelization strategy optimized for wafer-scale hardware:
- Massive Core Utilization: Efficiently leverages hundreds of thousands of AI cores
- Novel Distribution Algorithms: Optimizes workload distribution across the mesh
- Memory Hierarchy Optimization: Exploits distributed on-chip memory architecture
3. MeshGEMM and MeshGEMV
First-ever GEMM and GEMV implementations designed for wafer-scale accelerators:
- Scalable Matrix Operations: Optimized for mesh-connected AI cores
- Memory-aware Computation: Leverages distributed memory architecture
- Energy-efficient Design: Minimizes data movement across the mesh
Performance Achievements
Accelerator Utilization
- 200× higher utilization compared to state-of-the-art methods
- Efficient scaling across hundreds of thousands of cores
Computational Performance
- GEMV operations: 606× faster than NVIDIA A100 GPU
- Energy efficiency: 16× more energy-efficient than A100
- Full LLM inference: 10-20× speedups over A100 GPU clusters
System Comparison
Outperforms existing systems:
- SGLang: 10-20× faster inference
- vLLM: 10-20× faster inference
- GPU clusters: Significant energy and performance advantages
Technical Impact
WaferLLM addresses the fundamental mismatch between:
- Current LLM systems: Optimized for shared memory architectures (GPUs)
- Emerging AI accelerators: Wafer-scale distributed architectures
The system opens new possibilities for:
- Massive-scale AI inference: Leveraging wafer-scale manufacturing
- Energy-efficient AI: Reducing power consumption through optimized parallelism
- Cost-effective deployment: Better utilization of advanced AI hardware
Open Source Contribution
WaferLLM is open-sourced at https://github.com/MeshInfra/WaferLLM, enabling:
- Research collaboration: Advancing wafer-scale AI research
- Industry adoption: Practical deployment of wafer-scale systems
- Educational use: Learning about next-generation AI architectures
This work establishes the foundation for the next generation of AI inference systems, designed to exploit the unique advantages of wafer-scale AI accelerators.