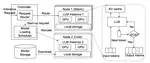
ServerlessLLM, a serverless inference system for Large Language Models (LLMs), enhances performance by leveraging GPU server resources efficiently. It minimizes remote checkpoint downloads, optimizes checkpoint loading, and prioritizes locality-driven server allocation for improved latency. Through innovative checkpoint design, multi-tier loading, and live migration, ServerlessLLM outperforms existing systems by 10 - 200X in latency for LLM workloads, as demonstrated in extensive experiments.
Yao Fu, Leyang Xue, Yeqi Huang, Andrei-Octavian Brabete, Dmitrii Ustiugov, Yuvraj Patel, Luo Mai